Enable GPUs for your Zeet Projects
Zeet supports deploying workloads to GPUs to leverage Hardware Acceleration. Common customer use-cases for GPUs are image and video processing, AI model training and inference, and data analytics.
Zeet currently supports GPUs for projects running on GCP, AWS, and CoreWeave Clusters. GPU availability may vary depending on the specific availability status of your cloud provider, so you should ensure you have quota capacity in your cloud provider's account.
For more information regarding GPU SKUs across all cloud providers and their respective pricing details, check out GPUCost.com.
Deploying GPUs to GCP
1. Enabling GPUs for GKE Clusters
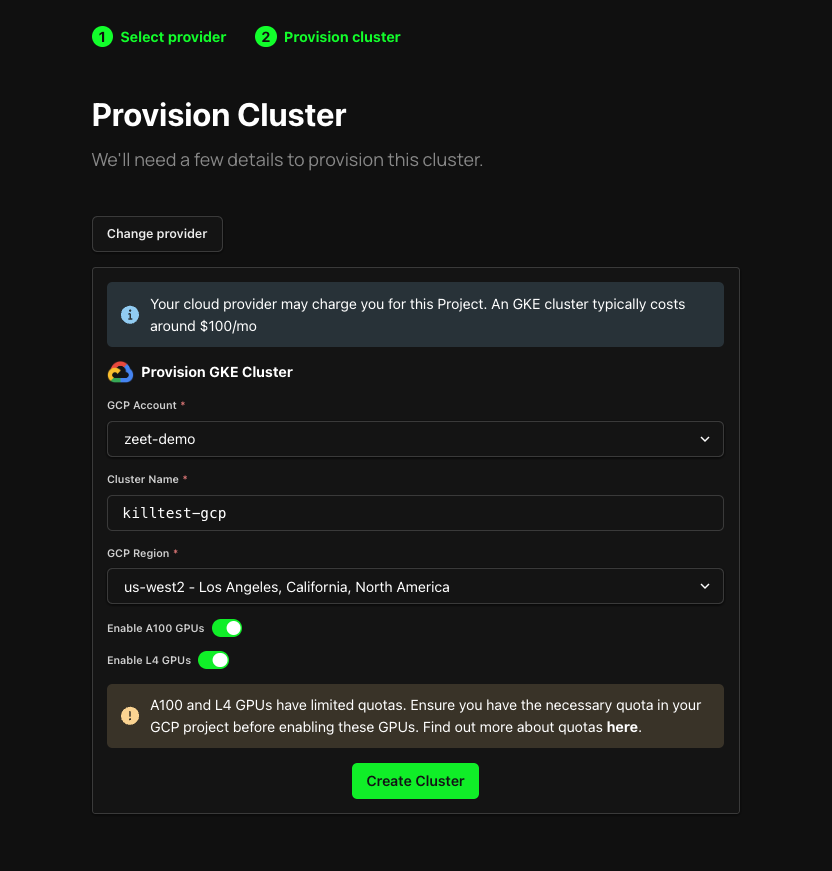
When you create a GKE Cluster using Zeet, you'll be granted access to all the GPUs accessible on GCP, with the exception of A100 and L4 GPUs. A100 and L4 GPUs come with restricted allocation quotas, so you'll be asked to confirm whether you have the sufficient quota during the cluster creation stage.
By default, Zeet will allocate all available GPUs in that particular region / zone. GCP supports different sets of GPUs in each region, documented in their documentation.
If you wish to include A100/L4 GPUs in your cluster, you can enable them during the cluster creation process by toggling the switch provided. However, it's important to note that you must confirm that your GCP project has the required quota allocation.
2. Select GPU for Zeet Project
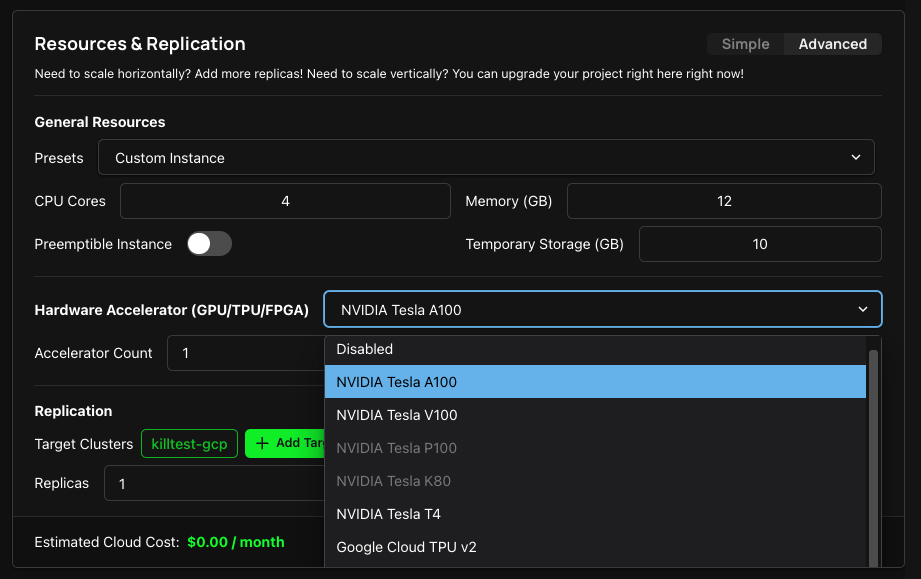
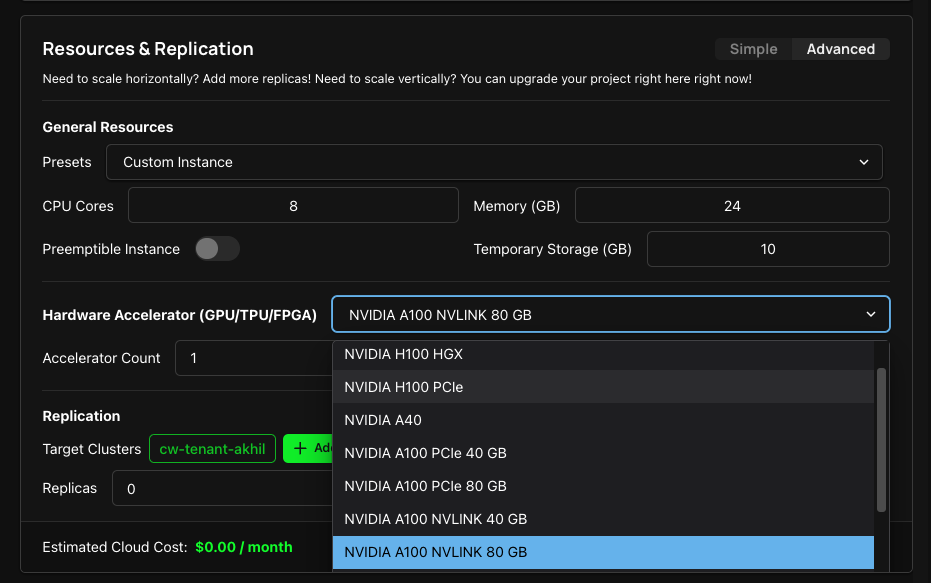
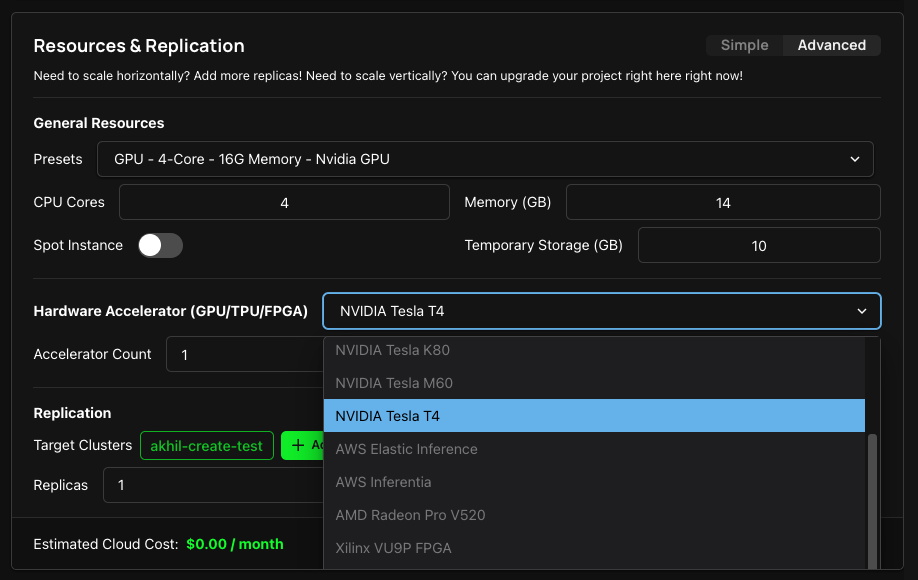
Once you created a cluster, you can deploy a Project and select the GPU of your choice in the Resources & Replication section of your Project settings, as long as the particular zone has support for such GPU. Refer to the above link for the list of GPU supported in the zone.
By default, Zeet allocates one GPU instance for each GPU type, which is sufficient and most effective for most workloads. However, if your workloads require more than one GPU, you can try the following solutions:
For advanced users, this option allows you to take full control of your cluster, handling the management completely to you. Namely, you will need to manage your cluster's full lifecycle, including Terraform definitions and helm packages.
Deploy a custom node pool
You may deploy a Terraform module in your Zeet dashboard to create your custom node pool. This will allow you to customize your node resources, including the number of GPUs. Check out terraform-google-modules on how to create a node pool with custom resources with Terraform.
Bring your own cluster
By bringing your own cluster and connect it to Zeet, you can configure cluster resources outside of Zeet, while still getting the convenience Zeet provides. Just take the kubeconfig of your cluster, and select "Connect an existing Kubernetes cluster" in the cluster creation page.
Ask Zeet support
Our support is always here to help if you have questions figuring out your best path. File a ticket in Support Center, and we will get back to you shortly.
Deploying GPUs to CoreWeave
Zeet supports deploying to all available GPUs on CoreWeave out-of-the-box. Simply attach your CoreWeave cluster and you can enable GPUs in the Resources & Replication section of your Project settings.
Deploying GPUs to AWS
At present, Zeet makes available a limited set of GPU SKUs for users in the Zeet Dashboard. To get access to other GPUs for AWS, please contact Zeet Support.
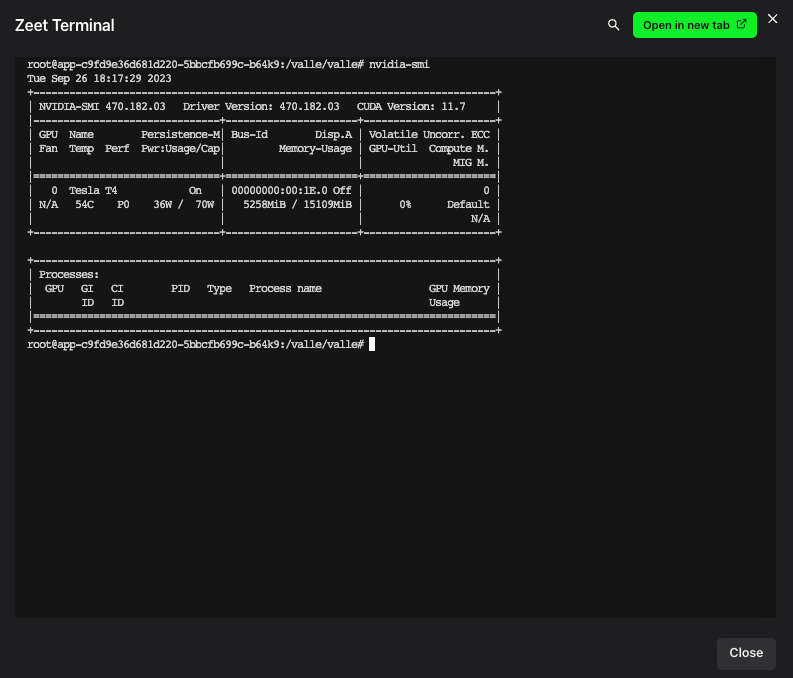
How to verify GPU status with nvidia-smi
Nvidia-smi is a command-line utility provided by NVIDIA for monitoring and managing the performance of NVIDIA GPUs. You can confirm the GPU status for your deployment on Zeet by launching the Zeet Terminal from the Project Overview page and running the nvidia-smi command. This will retrieve real-time information and status about the NVIDIA GPUs installed on your Zeet deployment.
How to enable GPU Monitoring
For comprehensive GPU monitoring, you can deploy Zeet's GPU Operator Blueprint, which installs Nvidia's GPU Operator as well as some other services to manage and monitor your GPU. Once deployed, Zeet will export GPU metrics to Prometheus, allowing you to gain insights into various aspects of GPU performance.
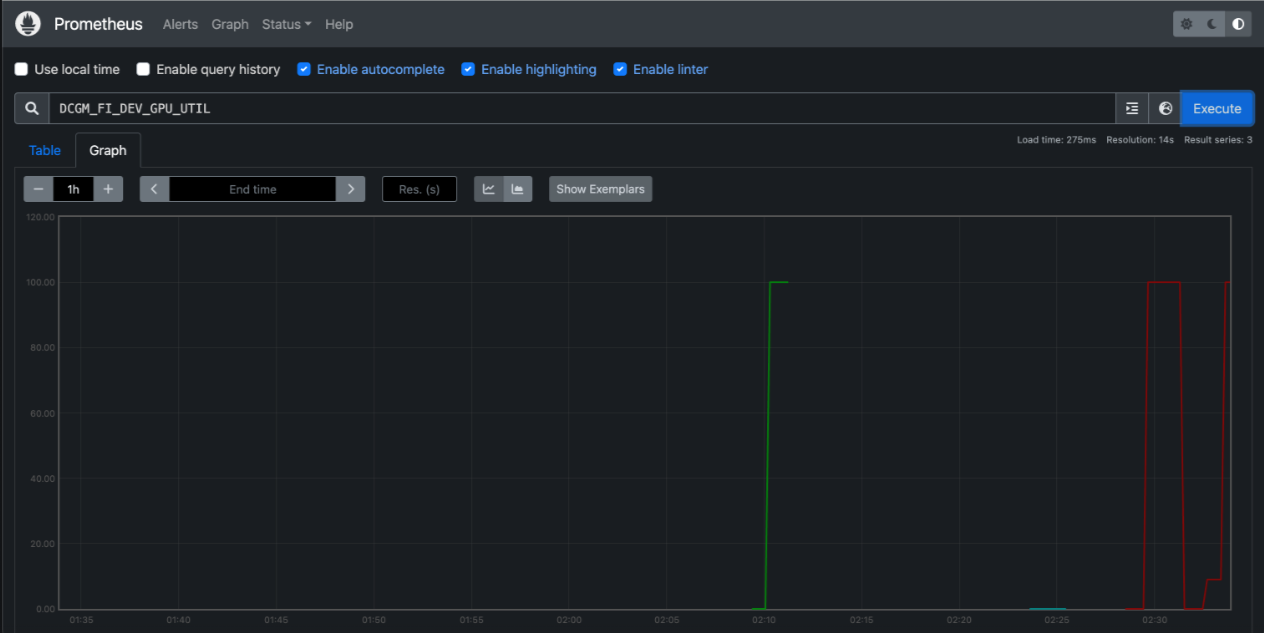
In the screenshot below, you can see a query for DCGM_FI_DEV_GPU_UTIL, a metric from Nvidia's Data Center GPU Manager (DCGM) suite designed for monitoring and managing GPU resources. You can easily extend your monitoring capabilities by querying other DCGM metrics such as memory utilization, ECC errors, and more. For a complete list of available metrics, refer to Nvidia's documentation.