Pinecone DB
Pinecone is a managed vector database service designed for high-performance search and similarity matching, particularly suitable for handling large-scale, high-dimensional vector data.
This guide covers how you can use Zeet's official Pinecone DB Blueprint to spin up a Pinecone Db instance in seconds!
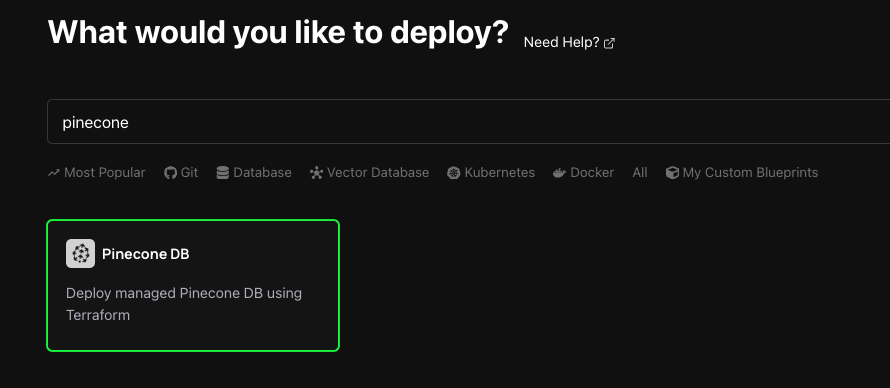
1. Select Pinecone DB Blueprint
To get started, head over to the Zeet dashboard and navigate to the Create New Database menu. Here, select the PineconeDB Blueprint.
2. Configure Blueprint for Deployment
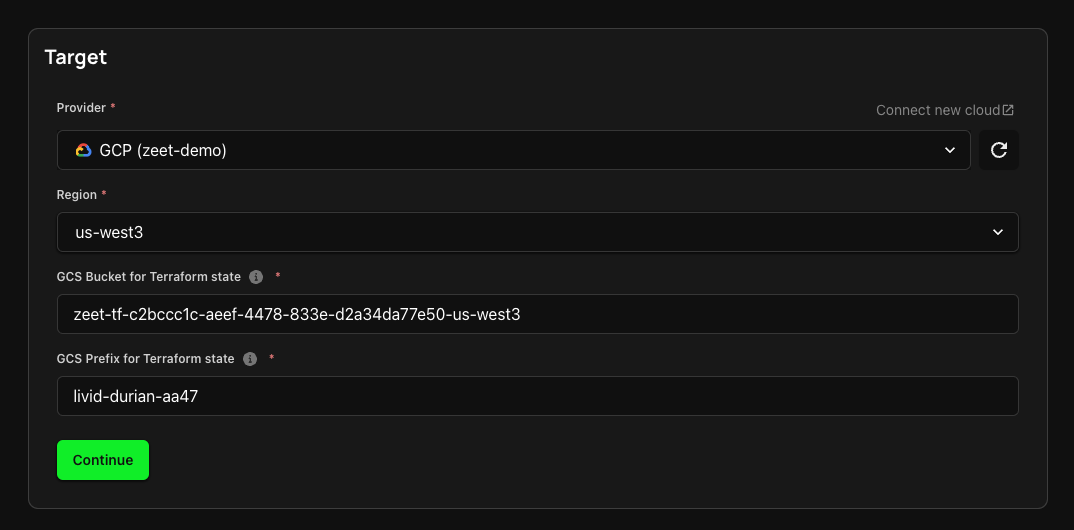
1. Select Deploy Target
The first step in configuring your deployment is selecting your Deploy Target. Zeet's Pinecone DB Blueprint utilizes Terraform under the hood to provision a Pinecone DB instance in your cloud account. Note that Zeet only supports Terraform-based blueprints for AWS and GCP.
2. Configure Inputs
The next step is to configure the required inputs to spin up a Pinecone index.
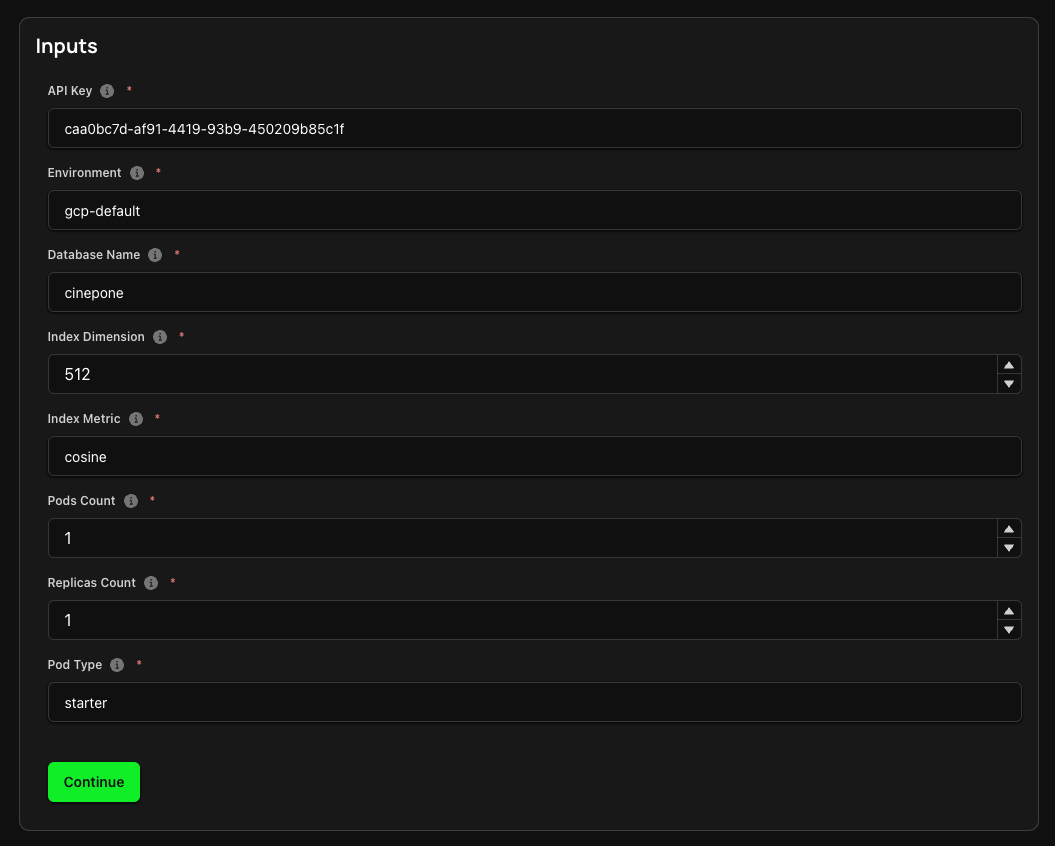
This includes:
- API Key and Environment: Your Pinecone API Key. You can find this in the API Keys page of your Pinecone dashboard.
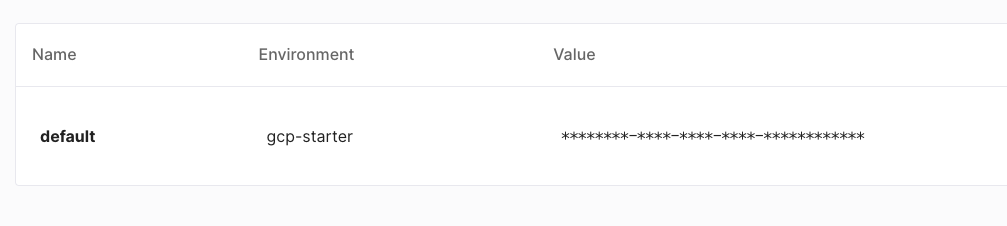
- Database Name: This refers to the name of the new index database to be created.
- Index Dimension: This refers to the number of dimensions or features in the vector space used to represent the data.
- Index Metric: This refers to the method used to measure similarity between vectors, with options including cosine, Euclidean, and dot product.
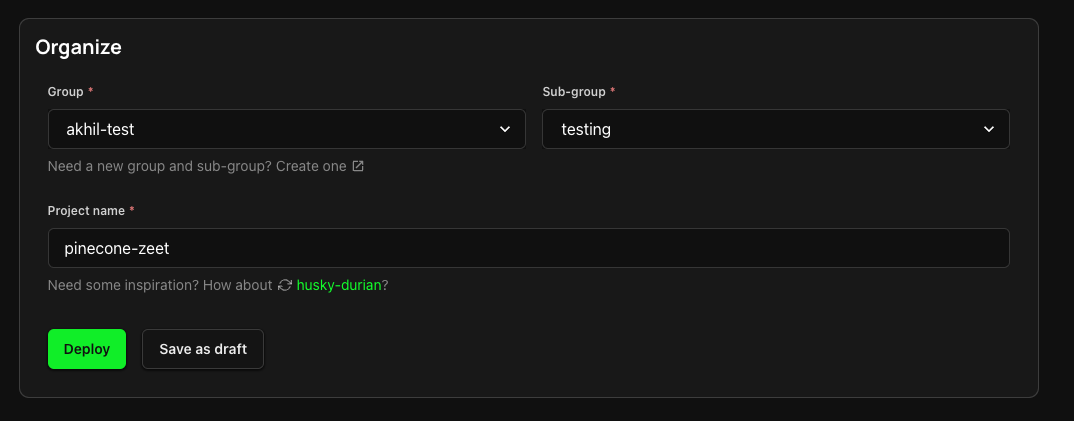
3. Finalize and Deploy!
You're so close! Your Project is within reach, and all that's left is to name it and choose a home for it. Pick the Group and Sub-Group, or create new ones and deploy your Project right away, or save it as a draft to deploy it when the time is right.
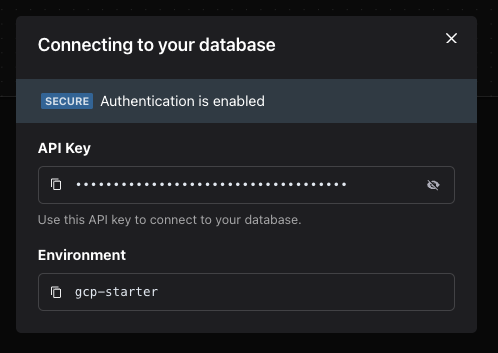
3. View Database Connection Info
Once deployed, you can click on the Connection Info button at the top-right corner of your Project details page to find the relevant connection information for your Pinecone Database. You can also find this database in your Pinecone dashboard.